はじめに
Orangeは汎用的なデータマイニングおよび機械学習ツールです。
今回はGUIを用いた利用方法を紹介します。他にPythonのライブラリもあります。
GUIの雰囲気はhttps://orangedatamining.com/screenshots/を見ればわかると思います。
使用環境
今回のレビューにおける使用環境は以下のとおりです。
– Mac OS
– 1.4 GHz クアッドコアIntel Core i5
インストール・コンパイル方法
ダウンロードページから自分のOSに合ったものをダウンロードします。
今回はmacOSの「Orange for Intel」をダウンロードしました。
macOSの場合にCPUを確認する方法
メニューバー左端の林檎マークから「このMacについて」を選択します。
「プロセッサ」の項目でApple siliconかIntelかがわかります。
実行方法
入力ファイルの準備
Orangeを使う前に入力ファイルの準備の仕方を説明します。
入力形式として使えるのは以下です。
| Basket | .basket .bsk |
| コンマ区切り | .csv .csv.gz .gz .csv.bz2 .bz2 .csv.xz .xz |
| Excel | .xls .xlsx |
| 学習済みのOrangeのデータ | .pkl .pickle .pkl.gz .pickle.gz .gz .pkl.bz2 .pickle.bz2 .bz2 .pkl.xz .pickle.xz .xz |
| タブ区切り | .tab .tsv .tab.gz .tsv.gz .gz .tab.bz2 .tsv.bz2 .bz2 .tab.xz .tsv.xz .xz |
さらにGoogleスプレッドシートの共有リンクなど、URLを入力することでデータを取ってくることもできます。
入力ファイルは基本的な表形式と同じく「ヘッダー1行+データ」が基本となります。
Orangeではこれに、「データ型」と「役割」の情報を追加します。
「役割」は以下があります。
| target | 主変数の列 |
| meta | 主に判別名、直接データ処理をされない列 |
| skip | 無視される列 |
| feature | 基本的なデータを扱う列 |
「データ型」は以下があります。
| numeric | 数値データ |
| categorical | 分類データ |
| datetime | 時刻データ |
| text | テキストデータ |
これらの「役割」や「データ型」は入力ファイルに無くても、あとでOrangeの側から変更可能ですが、事前に入力ファイルに明記することも可能です。
ただしその際の注意点として、Orangeの表示と名前が若干変わっており、「役割」は
| c(class) | target |
| m(meta) | meta |
| i(ignore) | skip |
| (空白)| feature |
「データ型」は
| c(continuous) | numeric |
| d(discrete) | categorical |
| t(time) | datetime |
| s(string) | text |
のように対応しています。
入力ファイルでの「役割」や「データ型」の書き方は2通りあります。
1つ目はヘッダーの2行目に「データ型」、3行目に「役割」を書く方法です。タブ区切り形式では以下のようになります。
sepal length sepal width petal length petal width iris comment
c c c c d i
class
5.1 3.5 1.4 0.2 Iris-setosa first-element
…
2つ目はヘッダーの各成分の前、「役割」を小文字で、「データ型」を大文字で書き、「#」で区切る方法です。タブ区切り形式では以下のようになります。
C#sepal length C#sepal width C#petal length C#petal width cD#iris i#comment
c c c c d i
class
5.1 3.5 1.4 0.2 Iris-setosa
…
2つの方法で順序が逆なので注意してください。
Orangeの使い方
Orangeへの入力の仕方、およびデータの可視化の方法を見ていきましょう。Orangeを起動します。
Welcome to Orangeでは「New」を選択します。
まずはウィジェットを追加しましょう。基本的な方法は
– 左の表の中からクリック
– 左の表の中から右の空白の部分にドラック&ドロップ
– 右の空白の部分をクリックしてそこから選択
の3つがあります。
基本となる「File」と「Data table」ウィジェットも追加すると次のようになるはずです。
左にFile、右にScatter Plotという名前の丸いアイコンが置かれています。
ウィジェットは普通に選ぶのも可能ですが、Filter…の部分に名前を入力すると探しやすいです。
各ウィジェットの横には点線が表示されていますが、左側は入力、右側は出力を意味します。
例えば、「File」の右側と「Data table」の左側を線で結ぶと、「File」での処理の結果を「Data table」に渡すことができます。
FileとScatter Plotが線で結ばれています。
ちなみに空白の部分に繋げると、ウィジェット選択画面が現れ、ウィジェットを追加しつつ線で結ぶことができます。
データの可視化
実際にデータ処理をしていきましょう。ここでは有名な「Fisher’s Iris data set」を使います。
(「Fisher’s Iris data set」とは、アヤメ科アヤメ属の花3種の各50個ずつにおいて、萼片の長さと幅、花弁の長さと幅の4種のデータを集めたものです。)
「File」ウィジェットをダブルクリックし、Fileから「datasets/iris.tab」を選択すると、次のような画面が表示されます。
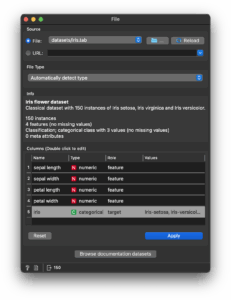
「Info」のうち、最初2行は「datasets/iris.tab.metadata」を自動的に読み取ったものです。
残りの行から、「150個のデータからなる」といったデータセットの情報を確認できます。
また「Columns」の部分にヘッダーの「名前」「データ型」「役割」の情報があります。
ちなみに、上述の方法で「データ型」や「役割」を指定しなかった場合はOrangeが自動で推定してくれますが、(主に「target」を)間違うことがあるので、その場合はこの画面から変更できます。
何度も使う予定のデータであれば、毎回直すのは面倒なので、「Save Data」というウィジェットに繋げて保存しておきましょう。
この状態で「Data Table」ウィジェットをタブルクリックすると、次のような画面になっていると思います。
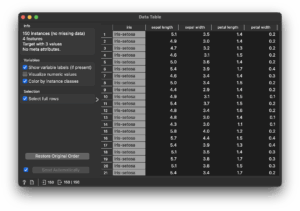
このように表形式にまとめてくれます。
さらに「Data Table」と「Scatter Plot」に繋げてみましょう。「Data Table」ウィジェットをタブルクリックすると散布図が表示されます。デフォルトでは最初の「meta」データ2つである萼片の長さと幅の散布図になります。
ここで、「Attribute」の「Size」から「petal length」を選ぶと次のようになります。
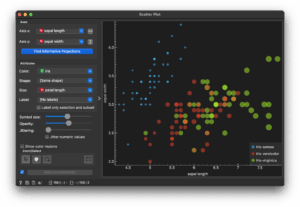
再び「Data Table」を開き、26-75行目を選択しましょう。「Scatter Plot」を見てみると、次のように選択されたデータのみが表示されていると思います。
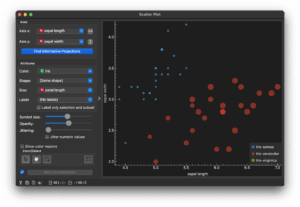
最後に、「Data Table」と「Scatter Plot」の間の線をダブルクリックすると次のような画面が表示されます。
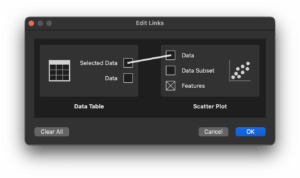
この上の線を消して、左の「Data」と右の「Data」を繋げると、最初のように全てのデータが散布図に表示されているはずです。
Paint Dataウィジェット
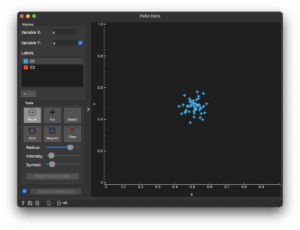
クリックした部分の周辺にデータ点をランダムに置くことで、データセットを作ることができます。用意された入力ファイルに組み合わせることも可能です。
クラスターの数を適当に変えたりなどが簡単にでき、アルゴリズムを試したい場合などに便利です。
アドオン
標準で実装されていないウィジェットはアドオンとして実装されいます。
メニューバーの「Options」の「Add-Ons…」から探すことができます。
アドオンをインストールし、一度Orangeを再起動すると使えるようになります。
チュートリアル動画
公式のチュートリアル動画「Getting Started with Orange」が存在しています。
ただしいずれもかなり初心者向けの内容になっているので、これらのデータ解析手法に一歳触れたことがない方が見流ものかと思います。
そもそもGUIである以上、使いながら覚えられることが多いです。特にウィジェットの検索機能もあるため、どこに何があるか分からないという事態は発生しにくいかと思います。
合計20個の動画を大別すると
– 01-04と08前半: Orangeの使い方の説明(もちろん今回のレビューで網羅してあります)
– 05-07,09-13,20: 既に数値化されたデータの処理・解析方法の紹介
– 08後半: Bioinfomaticsのアドオンの紹介
– 14-15: 画像解析のアドオンの紹介
– 16-19: 文書解析のアドオンの紹介
といった内容になっています。
終わりに
ということで、Orangeの基本的な紹介になりました。
今回紹介していないウィジェットは、クラスタリングやその性能評価などアルゴリズムの理解などを要するものが多いので、それらを紹介している資料やOrangeのウィジェットカタログを参考にしてください。