Guillaume Lambard,袖山 慶太郎(物質・材料研究機構)
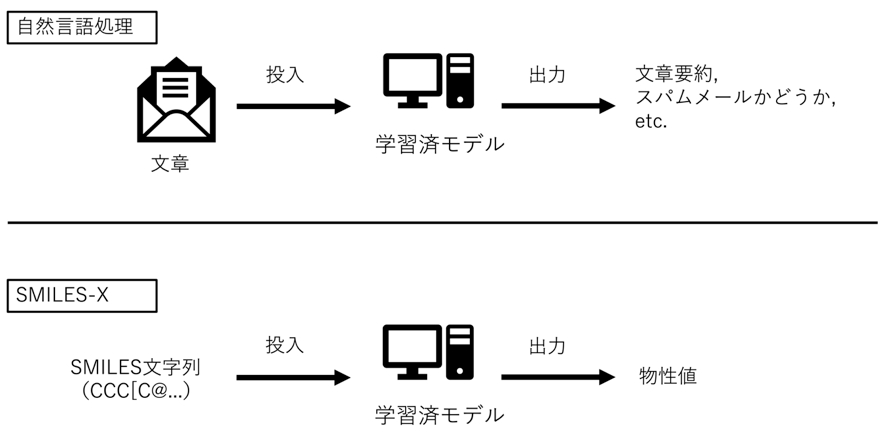
図1: 自然言語処理とSMILES-X
研究のポイント(着眼点)
- 文字列を計算機で扱う事は自然言語処理という分野で盛んに実施されている。一方、有機化合物を文字列で表すSMILES記法と呼ばれる方法がある。
- 本事例では、SMILESに対して自然言語処理の手法を用いる事で物性を予測するツール(SMILES-X)を作成した。結果として、既存のシミュレーションでの予想値よりも良いデータが見られるなど性能の高い事が分かった。
- SMILESを扱う際の困難として、データ量が自然言語処理のものよりも小さいという事がある。本事例では、小さいデータを解釈するための工夫が事前処理と機械学習の双方で行われた。今回の手法は自然言語処理や画像処理でもよく知られた手法であり、他の予測での応用も期待される。
ツール、データベースへのリンク
用語
SMILES記法
データ拡張
トークン化
アテンション
データ拡張
トークン化
アテンション
概要
有機化学ではSMILES記法と呼ばれる文字列を用いて物質の組成が表される事が多い。これに対して自然言語処理の手法を用いる事で物性の予測、探索をする試みが多くなされている。しかし、材料科学において自然言語処理の手法を用いる場合、多くの場合データセットの小ささが問題となる。本事例では、入力データとモデルの双方を工夫する事によって分子化合物の予測精度を上げる事を試み、5000個程度のデータセットで既存のシミュレーション結果より精度良く値を予測出来るようになった。
研究の背景
これまで物質の性質(物性)は実験において確かめられてきた。実験を実施するのは費用、時間的な負担が大きいため、計算機によって事前に性質を予測し、対象物質を絞りこむ事は有効である。近年では、物性をシミュレーションや機械学習によって予測する事が盛んに行われている。
有機分子においては、化学構造の表記方法としてSMILESと呼ばれる記法が広く用いられる。これは、分子の化学構造を文字列の形で表現したものである。本事例では、この記法を「言葉」のようにコンピュータに解釈させ、従来人間の言葉について用いられてきた処理(自然言語処理)の手法を用いる事で有機化合物の物性予測をする事を試みた。
通常、自然言語処理を実施する場合は、大きなデータを扱う事が可能となっている。それに対し、有機化学では欲しい物理量に対するデータを十分な量取得出来ない事が多い。そのため、分子化合物を扱う時は通常の自然言語処理よりも工夫が必要となる。
有機分子においては、化学構造の表記方法としてSMILESと呼ばれる記法が広く用いられる。これは、分子の化学構造を文字列の形で表現したものである。本事例では、この記法を「言葉」のようにコンピュータに解釈させ、従来人間の言葉について用いられてきた処理(自然言語処理)の手法を用いる事で有機化合物の物性予測をする事を試みた。
通常、自然言語処理を実施する場合は、大きなデータを扱う事が可能となっている。それに対し、有機化学では欲しい物理量に対するデータを十分な量取得出来ない事が多い。そのため、分子化合物を扱う時は通常の自然言語処理よりも工夫が必要となる。
研究の内容、成果
本研究では入力としてSMILES記法の文字列のみを用い、出力として物性値を出力するアプリケーションSMILES-Xを作成した。SMILES-Xは入力データの前処理とアテンションと呼ばれる機構を持つニューラルネットワークモデルを特徴としている。
前処理においては、少ないデータから多くのデータを擬似的に生み出す工夫(データ拡張)と、データの意味をある程度解釈しやすいように(単語のよう、あるいは文法構造のような)記述子へと分割する処理(トークン化)を行っている。この処理により、学習データの増加、データの解釈性の向上が期待できる。
また、機械学習においては、その途中段階に自然言語処理や画像処理の分野でも盛んに活用されている「アテンション」と呼ばれる機構を加えている。このアテンションとは、注目すべき情報を選別する機構であり、これを用いる事で物性値の予測精度の向上が期待される。アテンション機構は自然言語処理や画像処理でよく知られた手法であり、これらの領域での予測精度の向上に寄与している。
本事例では、学習データとしてMoleculeNetにある5000程度のSMILESデータと物性値を学習させ、SMILES-XによってSMILES記法で与えられる分子の性質の予測を試みた。結果として、分子動力学(分子運動を計算機内でシミュレーションする手法)よりも高い予測精度が得られた。例えば、テストデータに対して水和自由エネルギーの実験値を予測し、誤差の平均値を評価すると、SMILES-Xにおいては分子動力学より誤差が24.5%小さい値となった。
また、注目した情報を分子構造とともに可視化する事も出来、ここからどの原子が物性に重要な性質を持っているのか、という洞察を得ることができる。これもSMILES-Xの有用な点となっている。
前処理においては、少ないデータから多くのデータを擬似的に生み出す工夫(データ拡張)と、データの意味をある程度解釈しやすいように(単語のよう、あるいは文法構造のような)記述子へと分割する処理(トークン化)を行っている。この処理により、学習データの増加、データの解釈性の向上が期待できる。
また、機械学習においては、その途中段階に自然言語処理や画像処理の分野でも盛んに活用されている「アテンション」と呼ばれる機構を加えている。このアテンションとは、注目すべき情報を選別する機構であり、これを用いる事で物性値の予測精度の向上が期待される。アテンション機構は自然言語処理や画像処理でよく知られた手法であり、これらの領域での予測精度の向上に寄与している。
本事例では、学習データとしてMoleculeNetにある5000程度のSMILESデータと物性値を学習させ、SMILES-XによってSMILES記法で与えられる分子の性質の予測を試みた。結果として、分子動力学(分子運動を計算機内でシミュレーションする手法)よりも高い予測精度が得られた。例えば、テストデータに対して水和自由エネルギーの実験値を予測し、誤差の平均値を評価すると、SMILES-Xにおいては分子動力学より誤差が24.5%小さい値となった。
また、注目した情報を分子構造とともに可視化する事も出来、ここからどの原子が物性に重要な性質を持っているのか、という洞察を得ることができる。これもSMILES-Xの有用な点となっている。
将来への展望
SMILES-Xによって、SMILES文字列を元に低コスト、高精度の予測が実施出来る事となった。自然言語処理の手法を用いる事で、分子動力学等の通常用いられるシミュレーション手法ほど計算時間をかけずに高い精度で水和自由エネルギーを導出する事が可能となった。本事例にあるように、自然言語処理などの分野で発達してきた手法を物性予測に応用する事で様々な物性について低コスト、高精度で求まるようになると期待されている。
参考文献
G. Lambard and E. Gracheva, Machine Learning: Science and Technology, 1(2), 025004, (2020)Ekaterina Gracheva, Guillaume Lambard, Sadaki Samitsu, Keitaro Sodeyama, and Ayako Nakata, Science and Technology of Advanced Materials: Methods., 1(1), 213-224, (2021)